

Now is the time to learn R for people analytics. Here’s how to get started.
An introductory guide



This article is meant to serve as both a starting point and a reference for those who are interested in learning R for people analytics. It was written in collaboration with Jason Hodson who has experience in a variety of people analytics organizations and has served as a great technical mentor for me. Because of the article’s length, we’ve included a table of contents. Please feel free to skip through and find content that is helpful for you, wherever you happen to be on your journey.
Intro note: In my last article, I speculated about whether programming skills will continue to be a differentiator of talent, given rapid advancements in large language models (LLMs) like ChatGPT. I argued despite LLMs’ ability to write code faster than people, the code still needs to be understood, edited, and fine-tuned by a knowledgeable person.
It’s conceivable that thanks to LLMs, yesterday’s advanced-level (10x) programmers will become 100x programmers, intermediate programmers will become 10x programmers, and people with no/little programming experience will, thanks to generative AI, start to incorporate more programming into their work. That’s the vision of Replit, a company that provides a web-based AI-assisted programming environment. Replit is Google to democratize programming, and their mission is to “bring the next 1 billion programmers online”.
Whether your goal is to become a data scientist, or to just learn enough to be dangerous, we hope this provides some encouragement that now is a great time for HR and people analytics professionals to learn some programming.
Contents:
What is R?
R is an open source programming language, meaning it’s free to use, and its real power lies in its crowd-sourced libraries of tools that anyone can use. Unlike general-purpose languages like C or Python, R was designed for a specific domain – in this case data analysis and statistics. You can think of it as the tool of choice for “data analysts who need to program”, versus “programmers who need to analyze data”.
So, why is this helpful for people analytics? The specialization that comes with being a domain-specific language means that R offers an exhaustive set of functions and libraries that make it easier to program complex operations that are commonly used in our field. For example, the following code will create a regression model in just one line and store it in the object “model”:
model <- lm(var1 ~ var2)Of course, there is more than one line of computation required to get your computer to run a regression model, but the vast majority of this computation is taken care of for you. Therein lies the beauty of R.
R vs. Python
When someone is thinking about learning a programming language in a data analyst or data science role, R and Python are the most likely to be considered. We aren’t going to argue that one is better than the other – this would be like arguing over whether dogs or cats are the better pet. Both languages have strengths and weaknesses, so your choice of programming language is really going to depend on which use cases are most important to you (plus – it’s nice to be dangerous in both, especially if you work with other coders who might need a translation).
People Analytics tends to skew towards using R – for reasons we’ll outline – so we’re focusing on R first. Especially when just getting started with programming, it is helpful to maximize your chances of someone on your team or another team within your department using the skill/technology you’re using. Compounding on this, the RStudio IDE is the most beginner friendly IDE available for free.
R’s popularity in people analytics can be traced back to R’s contributors: R’s libraries were designed by social scientists, for social scientists. In academia, R is especially popular in fields like sociology, psychology, economics, and political science, so R has packages for conducting analyses like structural equation modelling, factor analysis, and network analysis, which are all commonly used research methods in those fields.
These extensive and easy-to-use libraries for social science map very neatly to people analytics work. For some examples, R can be used to help design and validate a new survey, conduct a survival analysis for voluntary turnover, or use causal inference methods to evaluate an HR program or policy. It’s worth noting that Python also has some functionality in each of these areas, but it is more limited when compared to R.
The open source cheat code
If there really is no free lunch, open-source tools might be the closest thing. In this case all that is meant by “open source” is that no one/no company actually owns R. It is purely updated and maintained by volunteers. This is why you can get started using it for free!
The robust community surrounding R is where its true value comes alive. A primary example: people in the community made a free integrated development environment (IDE) to make R easier to use. This IDE, called R Studio provides an interface for writing and executing code, and is the recommended place to do so. It has a number of features that make learning how to use R in your day to day easier than other programming languages like Python. R Studio is now maintained by a company called Posit - you can download it and learn more about it here.
To make R even easier to use (sensing a theme here?), contributors to the R community can create a “package” and make it available to be downloaded by anyone. You can think of a package similar to an add-on in Excel or an extension in Chrome. Once you start using R, you’ll see how essential they are – packages really enhance and simplify any task you want to do. For example, ggplot2, one of the most popular data visualization packages available in R, allows you to create a bar graph in a few lines of code and edit the visualization with really simple commands. In theory, you could write all the back-end code for this yourself, but it would take significantly longer and require a heavy coding background.
In summary, you can get started using R, RStudio, and packages free of charge. All of this is supported by the community around R. It will feel like getting Chipotle, Jersey Mike’s, or whatever your favorite lunch is for free.
4 of the best use cases for R in people analytics
Automation
This may sound surprising, but we think that from a beginners standpoint, automation use cases are where you could start getting value out of learning R first. If you apply some basic principles you can start automating and/or streamlining current reporting tasks (we may expand on this in a future tutorial).
Think about the pesky report that you need to create on a recurring basis. If you’re like us, the more parameters (filters, exclusions, etc.) you have to remember, the more you dislike the task. Rather than filtering down raw data in Excel or pulling from a dashboard, if you point R to your data source, you can do all the filtering, creating calculated columns, renaming columns, deleting columns with R. This means each time you need to provide the report, you can just point your R code to the updated data and run the code. While not required, nor something all people learning R should worry about, there are ways to automate this further. If your data is in a database and your company has a version of R on a server with task scheduling capabilities, you can create a script that generates the report and sends an email to the necessary recipients of the report (yes, R can send emails). When we’ve been able to do this, we’ve found how freeing this can be. You can completely remove the need to think about these recurring reports going out, allowing you to spend time and headspace on other things.
The above automation use case is where most individuals should start, however below are a few more automation use cases to get you thinking about what is possible:
Automate the creation of PowerPoint decks
Simple natural language generation to describe data
Automated generation of an insight from your data
Speaking from Jason’s personal experience in the People Analytics space, this was one of the places he started leveraging R and continues today. When he came into my most recent role, there were a handful of reports he needed to manually distribute every week. While each report was not time consuming, they can add up. Plus, the cognitive load these tasks can put on you is often underestimated. By automating your simple reporting tasks, you don’t need to think about these reports unless someone has a question. During a normal week, this may not be the strongest value proposition, but what about when you’re handling multiple fire drills and have PTO coming up next week?
Statistics
Statistics is R’s first love. Even today after R has become much more multi-purpose, R still skews towards the statistics space in what it does best. Thinking about our experiences in the People Analytics space, a recurring theme is the missed opportunity to apply some basic statistics to enhance the value People data can bring to decision makers in HR.
Descriptive statistics (mean, median, standard deviation, etc.) are the building blocks of statistics and R makes them incredibly easy to calculate. What could take hours to calculate all of the descriptive statistics using Excel, can take seconds using R. Providing you easy access to these numbers in your work. In our experience, we find these particularly useful when working with new datasets or new populations we’re unfamiliar with in a familiar dataset. These simple statistics can help you grasp the dataset much quicker than you otherwise could by just scrolling through the rows in Excel.
While a step further on the complexity scale, but a giant leap on the value scale (in our opinions) is the usage of hypothesis testing. In the corporate world, you may hear this referred to as statistical testing or significance testing. Some examples of this are t-test, Chi square and ANOVA. The goal of this content is not to make you a statistics expert, so here is a Khan academy video that goes into a bit more detail on what this is. To provide a simple People Analytics use case, here is a hypothetical use case in the Talent Acquisition realm of HR:
A Talent Acquisition leader comes to you with a problem. They’re trying to convince a traditionally minded business unit to open up their hiring to multiple hub locations, rather than just the main home office. They point to another business unit that hires similar talent who has had success hiring in the hub locations, both by hiring quicker and increasing their overall applicant volumes. This is a textbook use case for a hypothesis test. Once you get your data prepped, you can compare the hiring speed and applicant volumes between the two business units and use a t-test to identify if those differences are statistically significant.
Data Visualization
R’s capabilities to create data visualizations are essentially endless, but if you’re well acquainted with a dashboarding tool like Tableau or PowerBI you may not see a lot of value in R’s data visualization capabilities right away. We certainly don’t want to overstate R’s capabilities and would encourage you to look elsewhere for dashboarding / BI tools (R Shiny adherents may disagree).
That said, R’s most useful data visualization capabilities lie in the smaller niches advanced statistical analyses. This graph from Jackson’s thesis research – a visual representation of a polynomial regression model – is a great example.
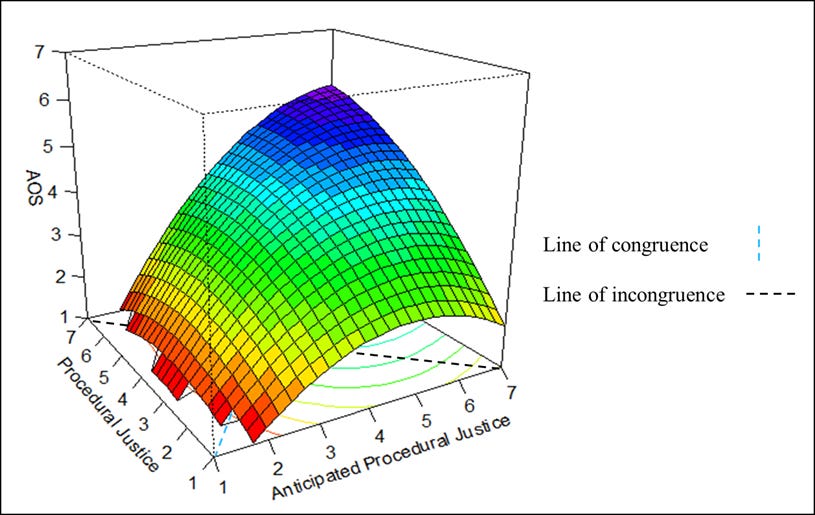
The primary package in R for data visualization is ggplot2. Its syntax – branded as the “grammar of data visualization” – is similar to dplyr (a data manipulation package, discussed below). The premise of the package is simple, you start with a type of graph and then build layers/features onto it. Features include labels, colors, axis labels, axis titles, etc.
The tradeoff for all of this customization is the time it takes to create your visualization. To create a line graph in PowerBI takes seconds, with further simple customizations taking only a few more seconds. Creating a visualization with R can be more time consuming. As you learn and get comfortable, you’ll start to find when you prefer to use which tool for your task.
AI/ML
In full transparency, we tend to use Python for AI/ML tasks, particularly NLP and predictive modeling work. That isn’t to say R cannot do AI/ML. It can, and has many packages available, but if you’re looking to dive into the cutting edge of language models and deep learning then Python is the gold standard.
That being said, in People Analytics we often work with sample sizes that are relatively small in machine learning terms (1000-10000), meaning that the “classical algorithms,” for which R has a plethora of packages, are preferable. If you’re looking for a place to start, check out the tidymodels package.
The learning curve for AI/ML can appear steep thanks to the complicated algorithms that lie beneath. However, text analysis is a good place to start exploring if you’re in a People Analytics role. Text analysis is much simpler to understand than most people would think. Combine that with how much text data is available in HR, doing simple text analysis can be a quick win to extract value from data that is underutilized. There are a number of text analysis packages in R and luckily most do a good job of explaining what is happening without getting too much into the math behind the scenes. This free eBook is a great place to start.
Tutorial: Downloading R and RStudio
As we mentioned above, R and RStudio are not the same thing, so we recommend that you download both. If you’re downloading this on a personal computer, your only option is to download from the below websites. However, if you’re on a work computer, there could be some more nuance.
Oddly enough, some companies just let you download R and RStudio from the internet. We’ve found this is the case because IT departments don’t want to deal with constantly upgrading the software. You can usually find out if this is the case by going to your company’s repository for downloading software to your computer. If you can’t find R or RStudio, it’s a good bet you can download directly from the internet. If this makes you feel nervous, you’re not alone (go to the link to download R and you’ll see why feeling nervous is justified). An extra step here could be to check with a team you know is leveraging R. This could be another data and analytics team, data scientists, data engineers, etc.
Download R here. This will take you to the CRAN home page where you can download R for Linux, Windows, or macOS. CRAN is a central repository for R. Remember that is looks like it’s a 20 year old website because its maintained by volunteers and the UI could actually be 20 years old. Make sure to download R first as RStudio will automatically look for R when you download it, making the setup easier.
Download RStudio here. This website identifies which operating system you have and will provide you the right one to download. Posit sells products beyond their free and open source tools, which explains why their website looks to be from this decade.
Tutorial: Installing Packages
Packages are one of the key features that make R such a powerful tool. Packages are collections of functions and other resources like built-in datasets that extend the functionality of R beyond its core capabilities. There are thousands of packages available on the Comprehensive R Archive Network (CRAN) and other repositories, covering a wide range of topics from statistical modeling to data visualization.
Why should you care about R packages? Well, for one, they can save you a lot of time and effort. Instead of having to write your own functions or import data sets from external sources, you can simply install a package that provides these features. This means you can focus on analyzing your data rather than worrying about the details of implementation.
Another reason to use R packages is that they are often developed and maintained by experts in their respective fields. This means you can benefit from the knowledge and experience of these experts, without having to become an expert yourself. And because many packages are open-source, you can inspect the code and modify it to suit your needs.
To use a CRAN mirror and download packages, first choose a CRAN mirror that is geographically close to you, so that you can download packages quickly. Once you have chosen a mirror, you can use the install.packages() function to download and install packages. For example, if you wanted to install the ggplot2 package, you would simply enter install.packages("tidyverse") in the R console. R will then download and install the package and its dependencies, if necessary.
install.packages("tidyverse")Tutorial: Reading and Writing Files
A major concept in writing code is “reproducibility”. When you’re getting started, you want to keep this in mind, but don’t let it be all-consuming. One main component to reproducibility is the best practice for reading and writing files. Here, we’ll assume you’re using RStudio on your computer, not on using RStudio on a server where your data is in a database.
The two main file types you will likely be working with are CSV and Excel. While opening either file type in the Excel application may look the same, R reads them differently.
Because CSV files are just text files, R reads them in natively via the function read.csv(file path). Below is an example of what this looks like. You’ll notice that the function read.csv() has an arrow pointing to something called “df”. This is telling R to read this CSV file and store is as an object called df. By doing this, we can now reference the data from this CSV file as df in the future.
Ex. df <- read.csv(“team_folder/project_folder/file_name.csv”)For Excel files, you’ll need to have a package to do this. This is because behind the scenes, Excel files are more complicated than just a simple text file. There are a number of packages you can use. Xlsx is usually the preferred. Below are the main steps to getting this to be usable for you.
The first step only needs to be done once. Once you’ve installed the package on your computer, its available to you until you delete it or get a new computer. The library() function is required each time you start a new “session”. This done to tell R to “activate” this package and make the functions within it available. While this may be an annoying step, it is necessary to not have all your packages active at one time. Especially as you leverage R more, you’ll start accumulating a lot of packages.
install.packages("xlsx")
library(xlsx)
df <- read.xlsx(“team_folder/project_folder/file_name.xlsx”)Once you’ve read in your data, done any necessary changes to it, now you’ll want to save these results back into a CSV or Excel format. The process for writing files is similar. In the write.csv() function, you need to tell it what data you want to save. In this case we’ll assume any changes you made went back into df. Then you need to tell it the folder path, with the file name. Lastly, this function by default will include a column at the beginning of your data called an index or row name. You rarely ever want this, so specifying row.names = FALSE will ensure this extra column isn’t included.
Write.csv(df, “team_folder/project_folder/filtered_file_name.csv”, row.names = FALSE)Using the same xlsx package, Excel files would look like.
Write.xlsx(df, “team_folder/project_folder/filtered_file_name.xlsx”)Closing the loop on the reproducibility concept. Its preferred you’re saving these files to a shared space where others on your team can reference. This makes it easier for someone else on your team to step in and help if they don’t have to update the folder paths from your personal folder paths.
If you start googling how to do the above, you’ll see how many different ways there are to read and write files. These examples are only one way, so feel free to use them as a starting point, but explore your other options as you get more comfortable with R!
Tutorial: Data Manipulation (filtering, renaming, rearranging, etc)
There are many resources out there on using/learning R, however we observed many go down a specific path. Some are statistics based, some AI, some data visualization, etc. We wanted to have this content be more general for someone in the People Analytics space who is getting started with R. One of the common threads across is needing to understand how to edit your raw data into what you need.
Dplyr is part of R’s core “universe” called the tidyverse. While there are other methods to edit your data, dplyr is the standard within R. Posit, the main contributor to dplyr (there they go again giving us things for free), provides cheat sheets for most of their tidyverse packages. The one for dplyr can be found here. There are so many concepts within dplyr, so we’ll focus on the few you’ll want to know to get started.
Delimiter Syntax
As you’re Googling dplyr examples, you’ll find a greater than sign between two percent signs, “%>%”. This is dplyr’s delimiter. Think of it as a way to tell R it’s the next step. When you’re getting started, it may look confusing. However, this allows you to string together multiple functions, which reduces how many lines of code you need to do the same thing. Here is an example below where you want to filter and order your data set by the same column.
New_df <- df %>% filter(column_name_1 >= 1)
New_df <- df %>% arrange(column_name_1)Vs.
New_df <- df %>% filter(column_name_1 >= 1) %>% arrange(column_name_1)This reduces the amount of code you had to write by 25%. That may seem trivial now, but it really adds up as you write more code!
Filtering
As you saw in the example above, you’re able to filter a dataset with dplyr. Here are some tips and tricks for what you can do. If you’re familiar with SQL, this is the WHERE part of your query.
If you want to say “equal to”, you need to use double equal signs, not just a single. ==, not =
Does not equal is “!=”
You can use any combination of greater than, less than, greater than or equal to, or less than or equal to
Use multiple conditions, “&” is “and” and “|” is “or”
Group by and summarize
[Jason] Its pretty common to need to summarize your data. I’ll share a story on this when I first started writing in R. I didn’t know that dplyr could aggregate your data based on conditions, so I created multiple versions of my data and read them into R individually. Once someone showed me I could do all this from the same base dataset, I couldn’t believe I had been doing what I was doing. Everyone who takes on learning a programming language will collect multiple stories like that, so don’t be embarrassed by them, embrace them because it means you had the humility to learn!
Counter to the first example around using the delimiter to limit how much code you need, the group_by() and summarize() functions should be part of the same step. To parallel to SQL, the group_by() function is similar to GROUP BY in SQL. One nice thing is you don’t also need to use SELECT, because anything you group the data on will automatically be in your result. Then summarize() allows you to use an aggregation function to summarize your data. For example, sum(), mean(), or n_distinct() are common functions. Page 2 of the dplyr cheatsheet has a list of aggregation functions. A few examples are below. The columns you group by and summarize are the ones that will appear in your newly created object
Aggregated_df <- df %>% group_by(column_name_2) %>% summarize(sum_column_name_1 = sum(column_name_1))
Multiple_columns_aggregated_df <- df %>% group_by(column_name_2, column_name_3) %>% summarize(sum_column_name_1 = sum(column_name_1), avg_column_name_4 = avg(column_name_4))Joining
Dplyr also has built in join functions to bring multiple datasets together. All of the options are available on page 2 of the dplyr cheatsheet.
Joined_df <- df %>% left_join(df_2, by = c(column_name_1 = column_name_1))
Multiple_column_joined_df <- df %>% left_join(df_2, by = c(“column_name_1” = “column_name_1”, “column_name_2” = “column_name_2”))Other useful functions
We’d like to point out a few other useful functions to know. These pair really well with the data manipulation tips and will help you quickly understand your data quickly:
str(): Short for ‘structure’, this function provides information about the structure of an object like a dataset. You can use this to get a glimpse into the parameters of your dataset, such as whether variables are numeric or categorical.
describe(): This is a super useful function from the psych package that provides descriptive statistics for the entire dataset. This includes means, SD, min and max values for each variable, as well as measures of distribution like skewness and kurtosis. Being able to get all of this in one line of code feels like magic!
The lubridate package: This is a package in R that will be your skeleton key for those annoying date values. R can be a little tricky when trying to format date data in particular ways, but this package makes it easier with simple functions that help you convert dates to different formats. For example, you can use the ymd() function to convert a messy date value to a date object with "YYYY-MM-DD" format.
Best Practices
Here are some miscellaneous best practices we’d recommend. Much of this comes from our experience as we learned how to use R in our work.
Don’t edit your data before you bring it into R. You want to keep any changes within your R code, ensuring you can reproduce the same results. It can be very tempting when you’re struggling to figure out how to do something with R that you know is super easy in Excel. Resist the urge and learn how to do it in R – this offers a good practice opportunity and will be well worth it in the end!
Generally, R prefers column names without spaces. If possible, it is best to load in your data and change the column names to not have spaces in them. As a final step in your R script, you could re-rename the columns to look nicer if you’re creating a report that is going to someone.
Comment your code using the hashtag #. Not only will it make it easier for others to know what your code is doing, it will also make it easier for you to come back and remember what you’re doing. Many times, we have looked back at old code that wasn’t commented/documented very well and thought “what in the heck were we doing here?”. Especially at the beginning stages of learning R, you’ll find better and more efficient ways of doing things more frequently. This means the code you wrote 2 weeks ago could be using methods that are outdated for you personally, making it harder to remember why you did what you did.
Resources for where to go and learn
We hope this article has given you some helpful pointers on where to start. Below are some recommended options for you to continue learning R for People Analytics:
Free:
Handbook of Regression Modeling in People Analytics – this free eBook by Keith McNulty, a leading practitioner in people analytics
Tidy Text Mining R - another helpful free eBook focusing on text analysis
MarinStatsLectures - a great resource on YouTube with a variety of R tutorials
When in doubt, google it: Learning how to leverage Google when learning how to use R is important, even if you’re paying for something like Datacamp. Stack Overflow articles in particular we’ve found to be the most helpful. However, with anything on the internet, you’re going to come across various opinions (not all being “right”). It is pretty common for newcomers to learning a programming language like R to one a single “right” answer. Unfortunately, there are multiple ways to do the same thing and something you’ll need to get comfortable with.
Paid:
Craig Starbuck’s forthcoming book Fundamentals of People Analytics with Applications in R
Datacamp is one of the best options for learning R. It combines multiple teaching methods: videos, reading, and practice exercises. The individual plan is currently $25 per month, but they often run promos that can reduce the price. If learning R is part of your official development goals, it could also be worth seeing if your company would allow you to expense the membership fee. If you compare that to the cost of a single conference, $300 per year to aid in your development is a steal
 | A guest post by
|