

Putting Connections in Context
A Primer & Tutorial on Multiplex Networks for Organizational Network Analysis (ONA)



The ascent of ONA
Organizational network analysis (ONA) continues to be a rising trend in HR and people analytics due to its ability to provide insight into an organization's social dynamics. By applying network science to analyze the communication and collaboration patterns of workers, ONA can help leaders identify the most influential people in the organization, assess the effectiveness of collaboration between teams, and assess organizational culture. The 2022 People Analytics Trends report from Insight222 reported that 48% of organizations were using collaboration analytics or ONA tools, up from 39% the year before.
It’s no coincidence that the rise of ONA has mirrored the rise of the virtual working environment. As a greater proportion of work begins to live in the digital world, it has become easier to access data to model social networks. However, despite the tagline that often accompanies ONA (“how work really gets done”) these data sources offer a limited view into how work actually gets done, and how to improve it. Leaders want to know how work is getting done and whether it’s being done optimally, but in many cases, the right data is not collected, or data is not analyzed in a way that enables such insights. In this way, ONA can fall short in practice due to a mismatch between leader objectives and the data collection/analysis process.
In this article, we will explore how organizational networks are typically operationally defined by practitioners, discuss the limitations of these methods, and introduce a research-backed tool that practitioners can add to their ONA toolbelt, increasing the chances their analyses translate into action.
What’s missing in ONA: The right data, and context
Organizational networks can be defined in many ways. The edges, or connections between workers that make up a network can represent communications, social relationships, or even attitudes. How organizational networks are defined in practice, however, often comes down to technology and data availability.
ONA is most commonly performed using communication data, such as records of emails, chat logs, or meetings. The goal of tapping these data sources is to measure the actual workflow, versus what would be implied by the formal organizational hierarchy. As with any data collection, this approach can contain noise. Generally, we have to wrangle with three limitations:
Missing data on communication quality (vs. quantity): The most obvious limitation of communications data is that for reasons of both privacy and practicality, researchers usually don’t have insight into the content of communication. If we see that Jack and Jill are going back and forth a lot, we don’t know if this is intensive collaboration, or unproductive water-cooler chat. Inefficient meetings are another culprit here, and could make busy managers look more important than they are.
Mismatch between data and objectives: ONA can lead to misleading inferences if there is a mismatch between the type of data and the objectives of the analysis. Oftentimes a leader’s goal for ONA is to understand how work is getting accomplished in the organization, but the only data collected is communication data, which may not be a good proxy for who is completing tasks, has a scarce skillset, or institutional knowledge. A common example of this would be a project manager or product owner (PMO) role. These jobs require a lot of cross-functional communication in order to structure work. While the network may show PMOs as being critical for communication/coordination, but this may not be answering the fundamental question.
Missing context: Some roles may have an outsized impact on the communication network, but not be as business-critical as they appear. For example, executive assistants often send out emails on behalf of a senior leader, and they also may read and filter messages to the leader and flag what’s most important. If the data suggests that the assistant is sending the messages, understanding this context may lead us to recode the data to reflect that comms are coming from a senior leader. Essentially, the assistant is a hub for receiving emails and the leader is the hub for sending emails. But there is a broader issue of lack of context in general. Taking traditional HR analytics as an example, numbers are meaningless in isolation. A 12% turnover rate is not very meaningful until you tell me that we were at 8% last year, and the benchmark is 6%. In ONA, a certain individual may be central to the communication network, but how do we interpret that? In order to turn ONA data into insights, we need some sort of comparison or benchmark to help us make sense of the data.
We can view each of these problems as data problems, not necessarily ONA problems - there is a mismatch between the data collected and the insights that leaders want. So how do we bridge the gap?
ONA’s killer app: multiplex networks
While a full deep-dive on all three limitations is beyond the scope of this article, we would like to introduce one helpful method for adding context: multiplex networks – networks that have multiple layers or dimensions. An example of a multiplex network would be a team that communicates via email at work (email dimension) as well as via text outside of work (text message dimension).

There are many different uses for multiplex networks, but an ONA use case that is low-hanging-fruit is to establish a benchmark network representing what the actual workflow should look like from the leader’s perspective. Then, we can map our communication data against the desired workflow, allowing us to better understand whether there is a gap between the organization’s operating model and what’s actually going on. This gap between an organization’s benchmark workflow and the organization’s communication network is where the insight lies – and is where clues can be taken for action, whether that is adjusting the operating model or adjusting the communication flow.
A Tutorial on Conducting ONA with Multiplex Networks
Data structure and analysis
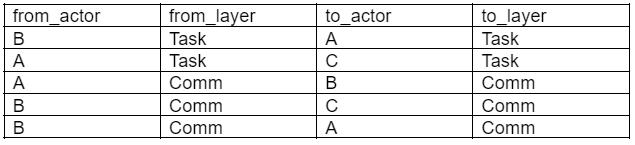
So how do we set this up? First, recall that a single-layer directed network can be represented through an edge list that has the following structure:
In this directed (connections are “from -> to”) communication network, we can see that B is clearly important for communicating with both Person A and C.
A multi-layer network is just a combination of single-layer networks. Imagine a network where the first layer is a map of the work design: who should Person A talk/work with to get work done? In the second layer, we want real communication: who does Person A actually talk with? Combining these layers gives us the following structure:

In this directed multiplex network, we can get more information. Person A works with C 5x to get task 2 completed. From a task perspective, Person B relies on less communication, only working with A once. However, they are still important to the communication network and must coordinate with Persons A & C.
Once our data is set up, the standard approach to analyzing multi-layer networks is to analyze each layer separately. From there we can answer several key questions:
Are the same actors present in both layers?
Do the same actors have the same connections in both layers?
Are the degree distributions the same across both layers?
Does the same person have the same degree distribution across layers?
An example from the multinet package in R
The multinet package provides a variety of useful functions that can be used to analyze multiplex networks. One example network comes from the Aarhus University Computer Science (AUCS) network collected by Dickinson et al. (2016). The data were collected at a university research department and include five types of online and offline relations. The population consists of 61 employees, including professors, postdocs, PhD students and administrative staff.
Creating and visualizing the networks
# Install the package:
install.packages("multinet")
#Call the package from your library:
library(multinet)
library(tidyverse) # we call this for easier data manipulation
#Call the AUCS network from the package and only keep the work connections and #communication (facebook) connections:
net <- ml_aucs()
delete_layers_ml(net, c("leisure", "lunch", "coauthor"))This next chunk is some processing to get the data for graphing, you can ignore if you’re not interested in a visual. Essentially, the first command imposes a layout formatting on the visual. The next command grabs the actors (nodes in the network) and their roles for plotting. Finally, the plot will generate network visuals for the two networks and a legend with the roles of the individuals in both networks.
l <- layout_multiforce_ml(net, w_inter = 0, gravity = 1) %>% filter(layer == "work" | layer == "facebook")
net_ppl = data.frame(actor = vertices_ml(net)[[1]])
roles <- get_values_ml(net, actors = net_ppl, attribute = "role")[[1]]
gr <- values2graphics(unique(roles))
plot(net, layout = l, grid = c(1, 3), vertex.labels = "", vertex.color = gr$color)
legend("bottomright", legend = gr$legend.text, col = gr$legend.col, pt.bg = gr$legend.col, pch = gr$legend.pch, bty = "n", pt.cex = 1, cex = 0.5, inset = c(0.05, 0.05))Analyzing the networks
Question 1: Are the top actors in both networks?
First get the top 6 actors from the work network by calculating the degree centrality for each actor in the work network, arranging it in descending order, and then using the head() function:
top_actors_work = data.frame(deg = na.omit(degree_ml(net, layer = "work")), actor = actors_ml(net, layers = "work")) %>% arrange(desc(deg)) %>% head() %>% mutate(type = "work")
# Do the same thing for the facebook network:
top_actors_fb = data.frame(deg = na.omit(degree_ml(net, layer = "facebook")), actor = actors_ml(net, layers = "facebook")) %>% arrange(desc(deg)) %>% head() %>% mutate(type = "facebook")
# Get the actors that are in both networks:
top_actors_both = top_actors_work$actor[top_actors_work$actor %in% top_actors_fb$actor]
# We see that 50% (3/6) of the actors overlap from both networks ("U4","U67", "U130")Question 2: Do the top actors have the same connections across layers?
# Get the connections (neighbors) for each node in each layer:
connects_work = lapply(top_actors_both, function(x) neighbors_ml(net, x, layers = "work"))
connects_fb = lapply(top_actors_both, function(x) neighbors_ml(net, x, layers = "facebook"))
#See what % neighbors from a top actor’s work network overlap with their #neighbors in their communication (facebook) network:
connects_fb[[1]][connects_fb[[1]] %in% connects_work[[1]]] %>% length(.)/length(connects_work[[1]]) # 33%
connects_fb[[2]][connects_fb[[2]] %in% connects_work[[2]]] %>% length(.)/length(connects_work[[2]]) # 50%
connects_fb[[3]][connects_fb[[3]] %in% connects_work[[3]]] %>% length(.)/length(connects_work[[3]]) # 56%
# Note: if you remove the code from the pipe (%>%) onward, you can get the
# exact names of the connections that overlap across layers.Question 3: Compare degree distributions across network layers:
Calculate the correlation between the actors’ degree centrality between layers. The closer that the correlation is to 1, the closer there is to a 100% match in the networks.
layer_comparison_ml(net, method = "pearson.degree")
# r = .54, so ~ 54% match between degree distributions.In summary, we can say that there is a moderate degree of overlap between the people who need to work together and the people who communicate with each other. In particular, it would appear that there are only a few “top actors” from the work network that are also top actors in the communication network. It might be that some of the important folks in the work network are not communicating well, or are facing some sort of communication bottleneck. Conversely, it might be that people who are communicating heavily in the network need to be better represented in the work network.
When comparing the top actors that are in both networks, the first actor has 33% overlap between the people they should talk to (i.e., the neighbors in their work network) and the people they are talking to (i.e., the neighbors in their communication network). This might warrant some investigation. Maybe the work network needs to be redesigned to reflect the reality that the first actor goes through. Or, maybe the first actor is working inefficiently and not talking to the right people.
In the end, while multiplex ONA is a powerful tool that can provide context to ONA and help diagnose potential areas of concern, it is not in and of itself an action. In general, data analysis - in its many varied forms - is not a replacement for effective action. Analytics is a tool that can be used to identify problems proactively or reactively, describe the reasons for why such problems occur, and provide potential solutions to such problems. It is up to leaders and managers to then act on such insights.
Reference tutorial: Loading in your own dataset
An example of a data structure that can be read into the multinet package. We will use the AUCS network below.
library(tidyverse)
library(igraph)
library(multinet)
## If you have your own data frame, then skip to Step 3
# Step 1. Draw from existing multiplex network
net <- ml_aucs()
# Step 2. Get the edges from the multiplex network, convert to data frame, and write to .csv
edges_ml(net) %>% as.data.frame() %>% write.csv(., "AUCS.csv")
## Prior to reading in the data, you may want to do some processing based on frequency of communication to reduce the edges.
# Step 3. Read in the csv and convert to data frame
net <- read_csv("~/AUCS.csv")
# Note: Columns may have to be in a specific order as follows
net = net %>% select(from_actor, from_layer, to_actor, to_layer) %>% data.frame()
# Step 4a: Create an empty list for storing the layers
layers = list()
for(i in 1:length(unique(net$from_layer))){
# Step 4b. Loop through the unique layers in the data frame. For each unique
# layer, convert it to an igraph object.
layers[[i]] = graph_from_data_frame(net %>% filter(from_layer == unique(net$from_layer)[i]) %>% select(from_actor, to_actor)
, directed = TRUE)
}
# Step 5a. Initialize an empty multiplex network
n = ml_empty()
for(i in 1:length(layers)){
# Step 5b. For each layer in the layers list, add it to the empty multiplex network. Name the layer based on the unique from_layer value.
add_igraph_layer_ml(n, layers[[i]], unique(net$from_layer)[i])
}
## Note: this code assumes from_layer = to_layer and is therefore suitable for # graphing edges at specific layers.
## This should be useful for the majority of the questions that practitioners
# want to ask regarding the overlap of comms/workflow networks.
## If you have edges that cut across layers, then this code might not work.
# Use the add_edges_ml function to supplement (see below).
intra_layer_edges <- data.frame(
actors_from = c("A", "A", "B", "A"),
layers_from = c("l1", "l1", "l1", "l1"),
actors_to = c("B", "C", "C", "C"),
layers_to = c("l2", "l2", "l2", "l2"))
Intra_layer_edges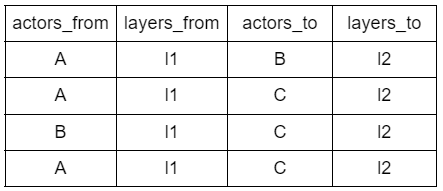
n = ml_empty()
add_edges_ml(n, intra_layer_edges)
## Note that even for this code, the layers_from must have consistent values
# (ex. all l1), and same for layers_to. | A guest post by
|
Appreciate the more technical overviews and examples. Hope to see more.